Contexte : Mon unique PC portable principal tourne avec Fedora depuis maintenant plusieurs années (j’ai quand même un dual-boot avec Windows 10 au cas où mais honnêtement, je ne l’utilise quasi jamais de la sorte). L’entreprise où je travaille, comme beaucoup d’autres boîtes, utilise Microsoft Exchange pour les e-mails, l’agenda et les contacts. Bien évidemment, à l’heure où j’écris ceci, même si Microsoft a fait plusieurs pas en avant ces dernières années vers l’univers « Linux » et que Microsoft Outlook est disponible sous Android, pour GNU/Linux et dans le cas qui m’intéresse plus précisément Fedora, aucun Microsoft Outlook à disposition (certains diront que via Wine c’est possible mais, sincèrement, je n’avais pas envie de « bricoler » de la sorte – cf. principe KISS).
Depuis des années voire même presque le début, j’utilise Mozilla Firefox. Il était donc +/- logique que je bascule vers Thunderbird pour mes e-mails. Par contre, et c’est là que ça coince, nativement, Microsoft Exchange n’est pas supporté. J’ai donc testé plusieurs modules complémentaires comme TbSync et Owl/Chouette. Hélas, aucun n’a répondu totalement à mes attentes. Le 1er, je n’ai jamais réussi à le faire fonctionner correctement et le second, pour lequel j’avais quand même payé une licence d’un an, m’imposait très très souvent de me reconnecter et était limité au niveau des agendas (partagés).
J’étais ensuite tombé sur le site web suivant : https://www.monperrus.net/martin/microsoft-exchange-calendar-from-thunderbird au gré de mes recherches. Et là, bingo ! Avec la passerelle Davmail, ça marchait du tonnerre ! C’était un peu du bricolage pour la partie « agenda » mais, sans utiliser le moindre module complémentaire dans Thunderbird, ça faisait parfaitement le job ! Et ça pourrait d’ailleurs parfaitement vous convenir en fonction de votre infra Exchange. Je dis bien « ça faisait parfaitement le job » car, du jour au lendemain, au niveau agenda, ça a commencé à déconner. J’ai bien évidemment essayé d’utiliser la dernière version en date de Davmail mais, dans ce cas précis, c’était encore pire et plus rien ne fonctionnait ! J’ai même désespérément tenté de contacter le développeur principal de Davmail. Hélas en vain (je ne lui jette pas du tout la pierre hein, il a sans doute mieux à faire) !
Bref, il fallait donc que je trouve une alternative. Je n’avais guère envie de revenir sous Windows 10 ou 11. J’avais alors envisagé un peu par dépit de tenter l’aventure avec macOS sur un MacBook Pro d’occasion (je n’ai toutefois pas [encore ?] franchi le pas).
Je suis donc tombé sur Evolution. Il faut dire qu’il n’y a pas 36 alternatives à Thunderbird (si ce ne sont quelques clients e-mails en ligne de commande). Je l’ai installé et je l’ai essayé. Résultat : échec. Je m’y suis sans doute mal pris. J’avais fait la configuration de mon compte e-mail manuellement. Et c’est sans doute là que ça a coincé (ça plus le fait qu’il me manquait un paquet pour la prise en charge complète d’Exchange). Je l’ai désinstallé et je me suis entêté à faire fonctionner quasi coûte que coûte Thunderbird et Davmail. Spoiler : en vain !
Puis, j’ai fait une nouvelle recherche sur le Net et là, bingo, je suis tombé sur le site web suivant : https://www.linuxtricks.fr/wiki/gnome-integrer-son-compte-microsoft-exchange-sous-linux Hourra ! Merci d’ailleurs à l’auteur de cet article ! Si j’étais tombé dessus un peu plus tôt, il m’aurait fait économiser de nombreuses heures de prise de tête.
Concrètement : il suffit d’installer les paquets evolution et evolution-ews (ce dernier permet la prise en charge de l’API Exchange Web Services (EWS)). Et après avoir configuré son compte, c’est à peu près tout ! Accessoirement, je recommande l’installation de gnome-calendar & gnome-contacts.
Dès que c’est installé, allez dans « Comptes en ligne » (via Paramètres système / Centre de contrôle ou directement en tapant « Comptes en ligne » dans le menu des applications) et ajoutez-y votre compte Microsoft Exchange (si pas présent sur votre système, installez le paquet gnome-online-accounts).
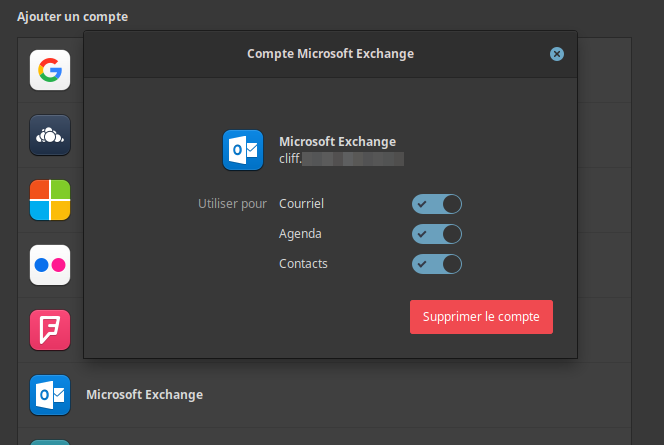
Patientez quelques secondes et ça devrait être bon. C’est tout ! Rien de plus !
Toujours dans mon cas, j’ai importé toutes mes archives Thunderbird sans le moindre souci. J’ai également refait 2 ou 3 règles pour appliquer des étiquettes automatiquement aux e-mails de la boîte de réception. Après quelques réglages ci et là (le dossier local d’archivage, la signature, la manière dont sont affichés les e-mails [grouper ou non par fils de discussion]) et je me retrouvais à quelques menus détails près avec ce que j’avais avec Thunderbird, prise de tête en moins.
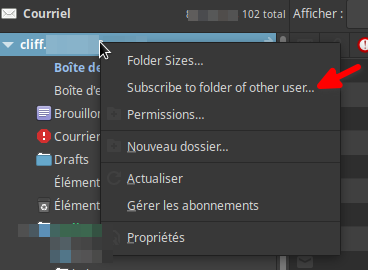
Petite subtilité pour ajouter un agenda partagé d’un-e collègue ou d’une équipe : il suffit de faire un clic droit sur l’intitulé de votre compte dans la partie « Courriel » d’Evolution est cliquer sur « Subscribe to folder of other user… ». Vous renseignez le nom du calendrier et dès qu’il apparaît dans les résultats, vous choisissez bien entendu « Calendar ».
Dans l’immédiat, j’ai retrouvé presque toutes mes habitudes de Thunderbird dans Evolution (comme par exemple convertir le contenu d’un e-mail en évènement dans l’agenda pour ne rien oublier – par contre, le fait de simplement appuyer sur la touche « A » du clavier pour archiver les messages me manque [ou alors, je n’ai pas bien cherché]). A voir bien entendu dans les semaines/mois qui viennent si des choses vont me titiller.
Bonus : via le terminal, il est possible de faire démarrer Evolution dans un mode bien précis (Courriel, Agenda, Contacts, …). Tapez evolution –help pour en savoir plus. Et, chose intéressante pour les sauvegardes, il suffit d’aller dans Fichier puis Archiver les données d’Evolution …. pour générer automatiquement une archive compressée tar.gz (malheureusement, pas faisable via la commande evolution [j’ai vérifié] et donc pas scriptable automatiquement en l’état).



